
On a rainy day, when the pitter-patter of raindrops orchestrates a symphony against the windowpane, I find solace in the realm of coding. I have embarked on countless coding journeys, each accompanied by its own set of challenges and triumphs. Just like the rain that occasionally dances unpredictably, coding too can have its share of unpredictable moments, where hiccups arise, and we must seek remedies to navigate through them.
In the vast landscape of software development, Spring Boot emerges as a beacon of hope, bringing forth a refreshing breeze of simplicity and efficiency. Like the gentle arrival of spring, it offers a renewed sense of enthusiasm, making the development process more enjoyable and manageable. Spring Boot empowers us to focus on crafting remarkable applications, while it handles the tedious and repetitive configuration tasks behind the scenes.
Now, let’s delve into a fascinating aspect of Spring Boot that has proven to be a valuable ally in building resilient and scalable systems — SQS, or Simple Queue Service. SQS, offered by Amazon Web Services (AWS), is a fully managed message queuing service that allows applications to communicate asynchronously by decoupling the sender and receiver. It acts as a reliable intermediary, ensuring messages are safely delivered between components, even when there are fluctuations in demand or potential failures in the system.
Working with spring boot and SQS is not new for me. Few years ago I worked on a spring boot project where I used SQS. Recently, I got the chance to start a green field project. Having witnessed the proven merits of SQS in the past, I eagerly chose to incorporate it into this new endeavor. However, to my surprise, I found myself stumbling upon unforeseen challenges that I couldn’t recall encountering before. Perhaps in my previous project, I joined the team when it had reached a certain level of maturity, and the configurations were already in place, skillfully handled by another team member. This time, however, my expectation of smooth sailing with minimal configuration for basic use cases was met with unexpected roadblocks.
In this write-up I’ll share the challenges I’ve faced and what I did to overcome those challenges.
At first I created a new spring boot project with spring initializer. I’m using spring boot version 2.7.7. As now I have bootstrapped the project now need an SQS instance to test our development. I don’t want to spin up a real sqs instance. To save some bucks, rather I prefer to deploy a local sqs with docker. Here is the docker compose:
version: "3"
services:
sqs:
image: roribio16/alpine-sqs
ports:
- '9334:9324'
- '9335:9325'
volumes:
- my-datavolume:/sqs-data
volumes:
my-datavolume:
Just for this demo I picked this roribio16/alpine-sqs image. It is lightweight, and also has an UI. Whereas localstack is a bit heavy.
Now a docker compose up should bring us an sqs up and running.
So here is the Idea. I’ll have a dto Task like this:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Task {
private String id;
private String name;
private String description;
}
And a controller like this:
@PostMapping("/task")
public void createTask(@RequestBody Task task){
log.info("Received task {}", task.toString());
queueService.publishTask(task);
}
So that I can POST tasks in this endpoint and this endpoint will call a method in queueService, that will have the necessary codes to publish the tasks to the sqs.
Later we will create a listener class that will receive the tasks from queue and do some heavy(!!) computation.. Nah, just some logs but should be able to convey the idea.
With spring-cloud-starter-aws-messaging we get QueueMessagingTemplate. It is an abstraction to easily publish/receive messages to queue. It also provides apis to configure various converters.
So, we are going to create a Bean of QueueMessagingTemplate. To construct functional QueuMessagingTemplate we will also need an instance of SqsClient. We will create both of them in a class named SQSConfig.
@Configuration
public class SqsConfig {
private final int BATCH_SIZE = 10;
private final String queueEndpoint;
public SqsConfig(@Value("${queue.endpoint}") String queueEndpoint) {
this.queueEndpoint = queueEndpoint;
}
@Bean
@Primary
public AmazonSQSAsync amazonSQSAsync(@Value("${spring.profiles.active}") String profile){
if(profile.equals("dev")){
return AmazonSQSAsyncClientBuilder
.standard()
.withEndpointConfiguration(new AwsClientBuilder.EndpointConfiguration(queueEndpoint,
Region.AP_SOUTHEAST_1.id()))
.build();
}
else{
return AmazonSQSAsyncClientBuilder
.standard()
.withRegion(Region.AP_SOUTHEAST_1.id())
.build();
}
}
@Bean
public QueueMessagingTemplate queueMessagingTemplate(AmazonSQSAsync amazonSQSAsync) {
return new QueueMessagingTemplate(amazonSQSAsync);
}
As in my dev environment I have my own sqs running at http://127.0.0.1:9334 which is not the usual sqs endpoint that’s why I instantiated with AmazonSQSAsyncClientBuilder mentioning the endpoint for the dev profile.
Now it’s time to create an implementation of the QueueService. We will take queueMessagingTemplate in the constructor and use it’s convertAndSend method to publish a message to our queue.
@Slf4j
@Service
public class QueueServiceImpl implements QueueService {
private final QueueMessagingTemplate queueMessagingTemplate;
private final String taskQueue;
public QueueServiceImpl(QueueMessagingTemplate queueMessagingTemplate,
@Value("${queue.task}") String taskQueue) {
this.queueMessagingTemplate = queueMessagingTemplate;
this.taskQueue = taskQueue;
}
@Override
public void publishTask(Task task) {
task.setId(UUID.randomUUID().toString());
log.info("Publishing task to queue {}", task);
queueMessagingTemplate.convertAndSend(taskQueue, task);
}
}
Let’s restart the server and hope everything compiles. Then run the following curl:
curl --location 'http://localhost:8080/task' \
--header 'Content-Type: application/json' \
--data '{
"name":"Task 1",
"description": "save the world"
}'
Now if we go to http://localhost:9335/ in our browser and click on the tab of our queue we will be able to see the message.
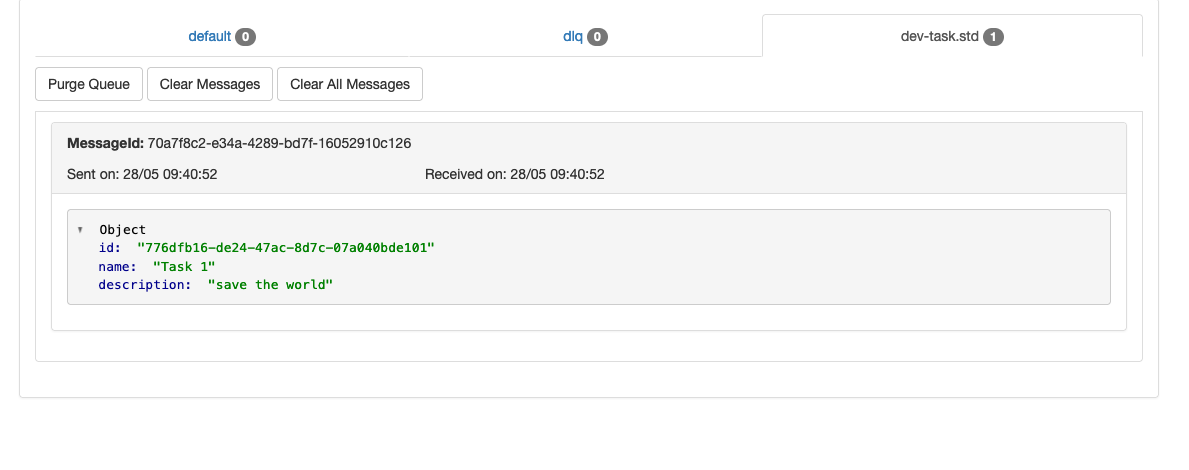
Message will be there unless a consumer receives the message and deletes it.
(For brevity I skipped the part of creating the queue. You can use an utility script or aws cli to do this.)
First Hiccup: Time module
So far, so good. Now I will change the Dto. I want to add an Instant field called arrivedAt. I will populate the field just before publishing to the queue. I have now updated the dto and publishTask method.
@Override
public void publishTask(Task task) {
task.setId(UUID.randomUUID().toString());
task.setArrivedAt(Instant.now());
log.info("Publishing task to queue {}", task);
queueMessagingTemplate.convertAndSend(taskQueue, task);
}
After restarting the application if we hit the curl again then …boom!
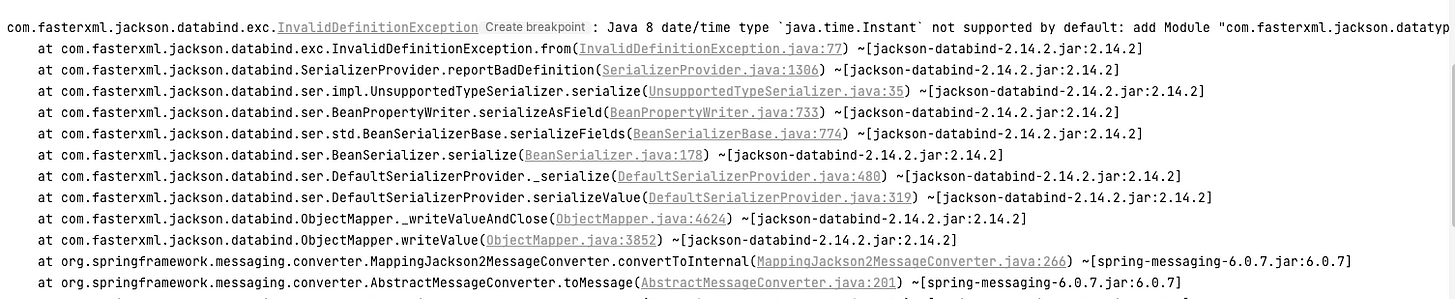
From this error message, I could determine that somewhere it is using ObjectMapper. An old friend of all Java developers and we all know when we use Instant, we have to instantiate ObjectMapper a bit differently. Which is easy. But the question is, how do we configure QueueMessageTemplate to use this custom ObjectMapper.
With some googling and reading the documentation, I found that by default it’s using SimpleMessageConverter. Found the source code here , I’ll be adding my own message converter like this. But before that, I’ll create a bean for ObjectMapper:
@Configuration
public class ObjectMapperConfig {
@Bean
ObjectMapper getObjectMapper(){
return new ObjectMapper().registerModule(new JavaTimeModule());
}
}
Now I’ll write my own message converter and there I’ll use the object mapper to convert the payload into string before giving the Message object to sqs.
My message converter implements a MessageConveter interface that has two methods fromMessage and toMessage. Right now, I am only publishing message to sqs. So I will add my custom implementation in toMessage method, and for fromMessage I’ll just copy the implementation from SimpleMessageConverter.
public class MyMessageConverter implements MessageConverter {
private final ObjectMapper objectMapper;
public MyMessageConverter(ObjectMapper objectMapper) {
this.objectMapper = objectMapper;
}
@Override
public Object fromMessage(Message<?> message, Class<?> targetClass) {
return null;
}
@Override
public Message<?> toMessage(Object payload, MessageHeaders headers) {
if (headers != null) {
MessageHeaderAccessor accessor = MessageHeaderAccessor.getAccessor(headers, MessageHeaderAccessor.class);
if (accessor != null && accessor.isMutable()) {
return MessageBuilder.createMessage(getStringPayload(payload), accessor.getMessageHeaders());
}
}
return MessageBuilder.withPayload(getStringPayload(payload)).copyHeaders(headers).build();
}
private String getStringPayload(Object payload){
try {
return objectMapper.writeValueAsString(payload);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}
Here actually, toMessage is also a copy from SimpleMessageConverter, the deviation is in the converting of the payload to string inside MessageBuilder’s withPayload method.
Finally plug in MyMessageConverter with QueueMessagingTemplate:
@Bean
public QueueMessagingTemplate queueMessagingTemplate(AmazonSQSAsync amazonSQSAsync, MyMessageConverter myMessageConverter) {
QueueMessagingTemplate queueMessagingTemplate = new QueueMessagingTemplate(amazonSQSAsync);
queueMessagingTemplate.setMessageConverter(myMessageConverter);
return queueMessagingTemplate;
}
Now if I restart the server and hit the cURL, the error should go away, and in the sqs’s web interface I should be able to see the published message with the new arrivedAt field:
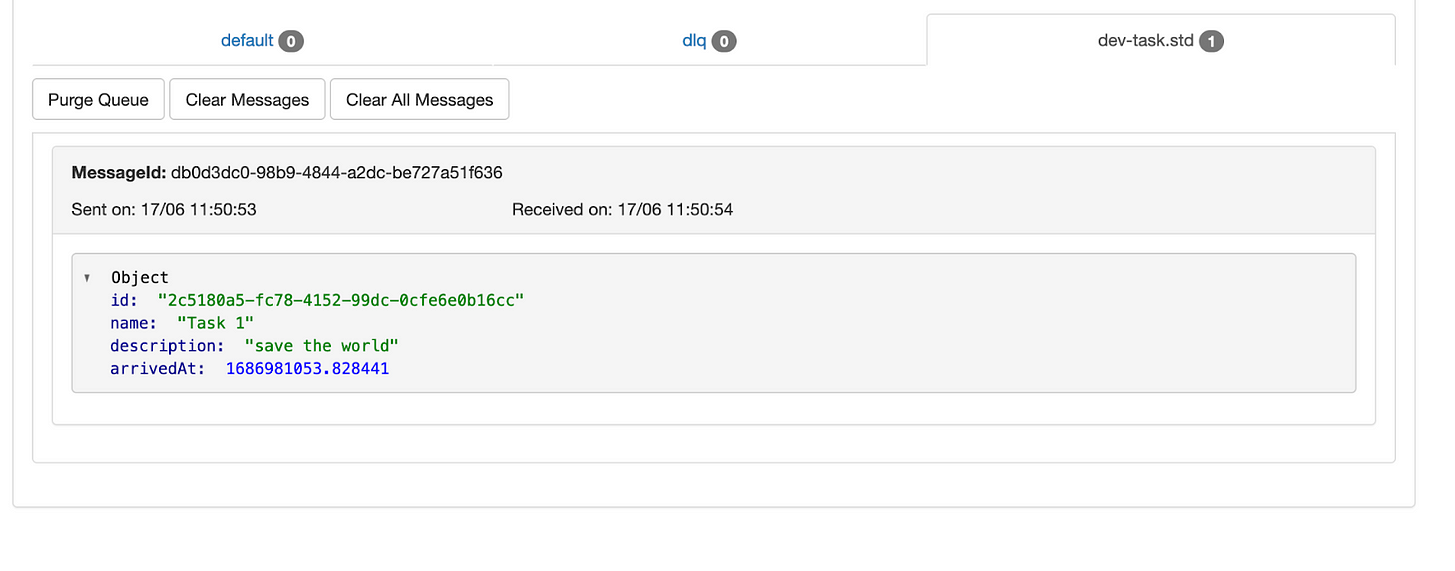
Second Hiccup: Listener Not Receiving Object
So far we managed to publish the message from the controller to the queue. This is a good time to start listening to the queue for messages. So we add a service and annotate a method with @SqsListener:
@Service
@Slf4j
public class TaskProcessorImpl implements TaskProcessor {
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ON_SUCCESS)
public void process(String task) {
log.info("Processing task {}", task);
}
}
This is enough for receiving messages as string payload. If we restart the application we can see the logs like this:
2023-06-28 12:44:21.522 INFO 10804 --- [enerContainer-2] x.r.sqsdemo.service.TaskProcessorImpl : Processing task {"id":"2813920f-589e-44ff-a38a-aeb87fd2b021","name":"Task 1","description":"save the world","arrivedAt":1687934661.470700713}
That means we are able to receive messages. We can now parse the string to object and do whatever we want.
But, can we receive the object in the method annotated with SqsListener?
Probably we can, let’s change the type from String to Task.
@Service
@Slf4j
public class TaskProcessorImpl implements TaskProcessor {
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
public void process(Task task) {
log.info("Processing task {}", task);
}
}
Now, restart the application and try to publish the message, you’ll see the console is again flooded with errors.
Because, we need to let sqs know how it could convert the receiving strings to object. So we add a bean of QueueMessageHandlerFactory.
@Bean
public QueueMessageHandlerFactory queueMessageHandlerFactory(ObjectMapper objectMapper,
AmazonSQSAsync amazonSQSAsync) {
MappingJackson2MessageConverter messageConverter = new MappingJackson2MessageConverter();
messageConverter.setObjectMapper(objectMapper);
messageConverter.setStrictContentTypeMatch(false);
QueueMessageHandlerFactory factory = new QueueMessageHandlerFactory();
factory.setAmazonSqs(amazonSQSAsync);
List<HandlerMethodArgumentResolver> resolvers = List.of(
new PayloadMethodArgumentResolver(messageConverter,null, false));
factory.setArgumentResolvers(resolvers);
return factory;
}
Next we will also need to annotate the first parameter of the process method as @Payload.
Now, we can receive objects directly from the listener.
Third Hiccup: Sleuth traceId not propagating
This was kind of surprising for me. Because, over the last few years. I never had to handle the propagation of sleuth ids in logs. As we are using sqs with clients or libraries from the spring eco-system, I expected that it would work out of the box.
But it didn’t. To achieve this, I had to read traceId, spanId from current span and add them in the headers before publishing the queue.
And on the listener side I have to start a new span after reading those ids from the message’s header then injecting it into a new trace context.
At first, let’s work on passing the traceId and spanId in the messages we publishing.
In QueueServiceImpl we add the following method:
private Map<String, Object> headers() {
return Map.of(
"SleuthTraceId",tracer.currentSpan().context().traceId(),
"SleuthSpanId", tracer.currentSpan().context().spanId());
}
Then pass the headers with convertAndSend like this:
queueMessagingTemplate.convertAndSend(taskQueue, task, headers());
Now, we are also going to need to capture the headers in the listener so that we can use them.
This is not hard. Just need to add a new argument which is a Map<String, Object> and annotate the parameter with @Headers annotation.
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
public void process(@Payload Task task, @Headers Map<String, Object> headers) {
log.info("Processing task {}", task);
}
If we restart the application, publish a new message and put a debug pointer in the body of process method and try to see what does headers is containing we’ll find something like this:
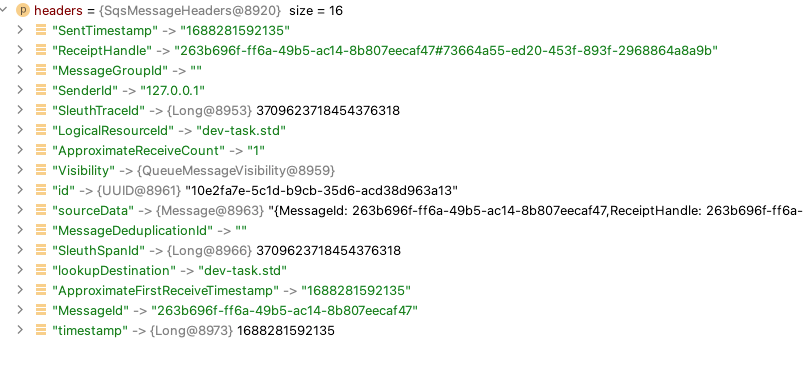
Let’s separate them and create a new traceContext with them, so that all the subsequent logs prints them.
So our modified process method looks like this now:
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
public void process(@Payload Task task, @Headers Map<String, Object> headers) {
var traceId = headers.get("SleuthTraceId");
var spanId = headers.get("SleuthSpanId");
TraceContext traceContext = TraceContext.newBuilder()
.traceId((Long) traceId)
.spanId((Long) spanId)
.build();
Span span = tracer.nextSpan(TraceContextOrSamplingFlags.create(traceContext));
try(Tracer.SpanInScope scope = tracer.withSpanInScope(span)){
log.info("Processing task {}", task);
} catch (Throwable e) {
throw new RuntimeException(e);
} finally {
span.finish();
}
}
Now logs will look like this:
2023-07-02 | 13:17:59.237 | http-nio-8080-exec-6 | INFO | xyz.ruhshan.sqsdemo.web.TaskController |9e0e13588a8f5aeb,9e0e13588a8f5aeb| Received task Task(id=null, name=Task 1, description=save the world, arrivedAt=null) 2023-07-02 | 13:17:59.237 | http-nio-8080-exec-6 | INFO | x.r.sqsdemo.service.QueueServiceImpl |9e0e13588a8f5aeb,9e0e13588a8f5aeb| Publishing task to queue Task(id=919e794e-ad48-4cc7-8102-6527ba98d4cd, name=Task 1, description=save the world, arrivedAt=2023-07-02T07:17:59.237655Z) 2023-07-02 | 13:17:59.245 | eListenerContainer-2 | INFO | x.r.sqsdemo.service.TaskProcessorImpl |9e0e13588a8f5aeb,9d462662007f81cd| Processing task Task(id=919e794e-ad48-4cc7-8102-6527ba98d4cd, name=Task 1, description=save the world, arrivedAt=2023-07-02T07:17:59.237655Z)
Yay! same traceId is present in the logs before publishing to queue and after receiving from queue.
Yeah, I know you are frowning.
Though it works. But it’s not clean. If we have multiple queues, we could have multiple listeners. And putting the same extract/construct/start span-code chunk in multiple places breaks the DRY principle.
What can we do?
There should be many ways. I’m sharing what I did.
I just made the following changes:
@Override
@SqsListener(value = "dev-task.std",deletionPolicy = SqsMessageDeletionPolicy.ALWAYS)
@MessageMapping
@InjectSleuthIds
public void process(@Payload Task task, @Headers Map<String, Object> headers) {
log.info("Processing task {}", task);
}
Yes, just added another annotation @InjectSleuthIds . But where did it come from? Unfortunately I had to create it. Then also used our old friend AOP to add the whole functionality of reading sleuthIds from sqs headers and spawn a new span with them.
It’s done in a separate class. But this is the most interesting method on that class:
@Around("@annotation(xyz.ruhshan.sqsdemo.aop.InjectSleuthIds)")
public Object injectSleuthIdsAroundAdvice(ProceedingJoinPoint proceedingJoinPoint) {
SleuthIds sleuthIds = getSleuthIdsFromPjp(proceedingJoinPoint);
TraceContext traceContext = TraceContext.newBuilder()
.traceId(sleuthIds.traceId)
.spanId(sleuthIds.spanId)
.build();
Span span = tracer.nextSpan(TraceContextOrSamplingFlags.create(traceContext));
try (var scope = tracer.withSpanInScope(span)) {
return proceedingJoinPoint.proceed();
} catch (Throwable e) {
log.error("Caught exception during proceeding join-point {}", e.getMessage());
throw new RuntimeException(e);
} finally {
span.finish();
}
}
Everything is pretty obvious for you if you know about aspect oriented programming. But if you do not. Here are my 2 cents for you:
- Making the method annotated with @Around(“@annotation(xyz.ruhshan.sqsdemo.aop.InjectSleuthIds)”) does a very special thing. Part of this method will be executed before the actual method execution which is annotated with @InjectSleuthIds, and part of the method will be executed after.
- ProceedingJoinPoint is an interface that gives us access to the arguments that our target annotated method is receiving and also methods to invoke the target method.
Using the helper method getSleuthIdsFromPjp I extracted traceId and spanId from the proceedingJoinPoint.
Then create the spanContext.
Then start the next span.
proceedingJoinPoint.proceed() is the invocation of our annotated target method. Wrapping this using try with resource statement and in the resource part running tracer.withSpanInScope(span) does the magic of printing the sleuth Ids in logs.
Don’t get me wrong. This will not only add sleuth ids for methods annotated with InjectSleuthIds annotation, but also all the subsequent methods in the invocation chain which could start from an annotated method.
I hope you have enjoyed this write-up. If you know better ways to deal with the issues I have faced, I’ll be very much obliged to know about them. Feel free to provide any kind of feedback.
Here is the complete source code of this demo.


